With love, Rajat_






Engineer, Creative, Tinkerer
My name is Rajat, and my fascination with building started when I was a kid and my brother showed me how to make simple games on our computer. I remember thinking "that’s, cool!" That moment of watching code become play opened a door I've been walking through ever since, from games to systems that genuinely help people.
Today, I build AI systems that do real work.Currently building a local-first inference engine that runs multiple models simultaneously with speculative decoding and continuous batching, a graph-based search engine that reasons over entity relationships in real time, a coding CLI for engineers who need to understand a codebase before they change it, and the orchestration infrastructure that ties it all together. I work across the full surface, from model serving and API design to the product interfaces people actually touch.
What holds my attention isn't any single system; it's the design problem underneath all of them. How do you make something powerful feel effortless? How do you build AI that earns trust instead of demanding it? How do you ship fast without building something you'll regret in six months? These are the questions I think about constantly, and SRSWTI is where I get to answer them in production, every day, for real users.
I believe what we make stands testament to who we are. In a world obsessed with what's easily counted—speed, cost, scale—I stay focused on what isn't: delight, care, humanity. I'm not interested in breaking things for the sake of innovation; I'm interested in building something so much better that the old way naturally becomes obsolete.
Outside of work, you'll find me on long walks, in the gym, or lost in music and photography. Books and architecture train my eye; conversations with interesting people shape my heart.

mémoire
mémoire enables any LLM to remember conversations, learn from interactions, and maintain context across sessions.

Cowork
Cowork is an open source agentic architecture where you describe an outcome, step away, and return to finished work—formatted documents, organized files, synthesized research, and more.

Mycelium
An open-source orchestration platform for long-running AI work, from research and code to documents, data analysis, and scheduled workflows.

- •Creations stand testament to who we are, our values and preoccupations.
- •Design should genuinely move humanity forward, not just meet price points.
- •Goal: enable and inspire people as builders in service of humanity.
- •Innovation is not about breaking things deliberately, only break as consequence of creating something better.
- •Progress requires conviction, vision, and resolve; it's not inevitable.
- •"Sincerely elevate the species"—millions engage with every detail, even cable packaging.
- •Users should feel "somebody gave a damn about me" when using your product.
- •Creating products is expressing gratitude to the species.
- •Reframe quality vs speed: ask "how can we work efficiently to create breathtaking quality?"
- •Words used to frame problems shape how we think.
- •Unintended consequences are inevitable, hope they're pleasant, but responsibility is mandatory.
- •Today's rate of change is too fast for society to create proper frameworks, unlike the Industrial Revolution.

Total LLMification
Transforming human knowledge from Human-First to LLM-First — beyond PDF-to-text into structured training signals.
The Problem with Modern Search
Search is drifting toward one-shot answers and embedding maximalism. Useful retrieval has to reason about absolute fit, relative preference, and whole-list context.
The Foundation of Life
Four coordinates of existence — Mind, Body, Spirit, and Vocation — and why genuine agency needs all of them.
Love and Habituation
We habituate to everything except the things we love. Those stay forever new.
Information Topology
What if information could find its own topology — graph theory, hierarchical determinism, and the velocity of knowing.
How Shipping Has Changed for Me
The gap between idea and working code has collapsed. Notes on agents, GPT-5, and shipping many projects at once.

- •Simplicity is not minimalism, it's expressing essence, purpose, and role in life.
- •Removing clutter without intention creates desiccated, soulless products.
- •Joy and humor are essential, not trivial; they've been missing in tech.
- •Your mental state while designing embodies the final work—anxiety creates anxious products.
- •The measurable trap: teams default to numbers (cost, speed, weight) because it's inclusive.
- •Much of what designers contribute cannot be measured numerically.
- •Delightful, joyful products are equally important and get used more.
- •Utility and aesthetics are not opposed—if something doesn't work, it's ugly.
- •When choosing between options, the more humane one is always correct.
- •Users sense both care and carelessness—most companies patronize consumers.
- •The inside matters: finish the back of drawers even if unseen, evolution is measured by what we do when no one watches.
- •Every business has an obligation to care about design, not just consumer electronics.
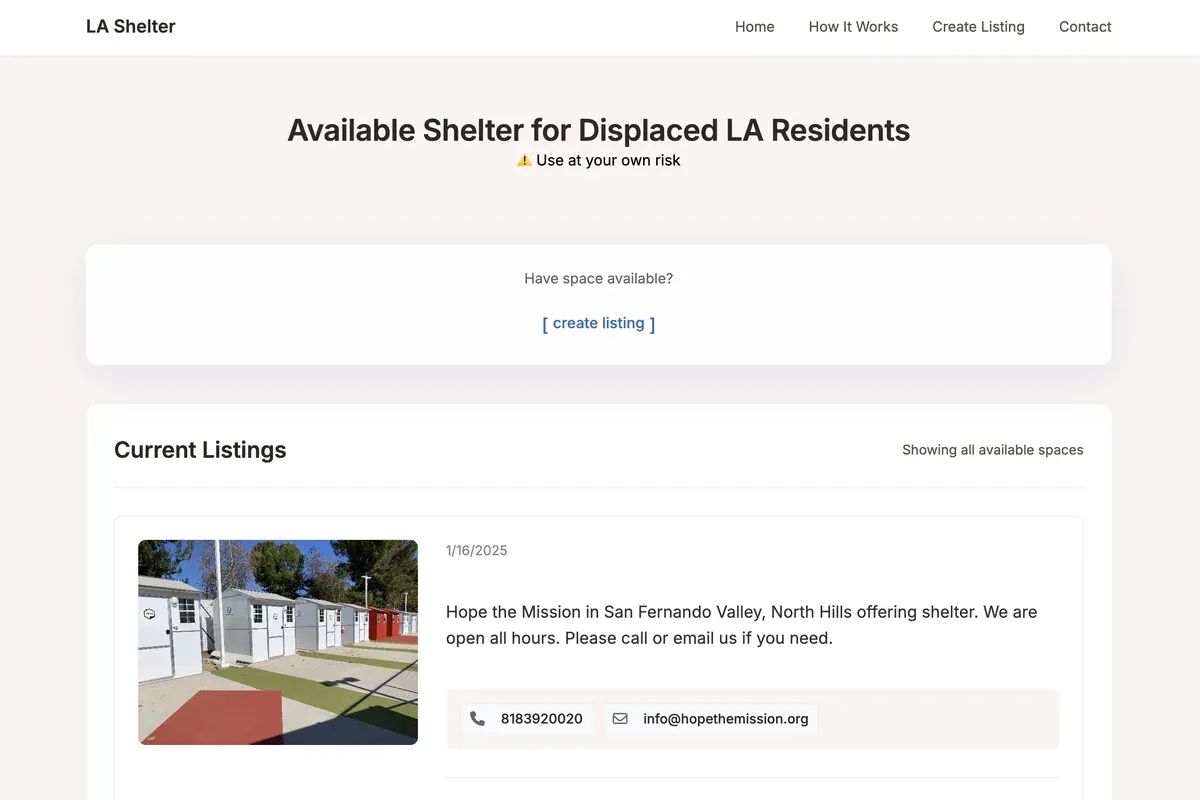
LA Shelter Platform
A platform to connect LA residents affected by fires with temporary housing options.



Currently
- •AI Software Engineer building production multi-agent frameworks
- •Building a personal OS on the side
- •Graduated with Masters from University of Texas
- •Running a moodboard Instagram page
Previously
- •Shipped an AI healthcare insurance app for Fidelity Investments
- •Launched a platform for listing available shelters and resources to help those displaced by the 2025 LA fires
- •Software Engineer at WeafTech, worked on data platform, distributed systems and machine learning projects with some very incredible engineers
- •Interned at TUV Nord and was part of digital transformation initiative for their industrial inspection division
- •Studied Computer Science at Birla Institute of Technology and Science
- •Launched a bite-sized news app at 18
- •Get good at something you actually love, because only love beats habituation.
- •Innovation serves progress, not disruption for its own sake.
- •Don't let old people screw you with student debt and fake prestige.
- •Exercise everyday.
- •Taste is a muscle.
- •Sweat the details.
- •A lot of things matter a little, a few things matter a lot.
- •Don't repeat talking points — you will live a boring, unfree life.
- •Face your fears — the worst outcome is death and that's coming anyway.
- •Embarrassment is the dumbest fear — literally nobody cares.
- •If motivations remain constant, you'll find ways to maintain care and control.
- •Work is important, but if you have nothing you love outside work, your brain becomes unbalanced and brittle.
- •Great outfits should be repeated.
- •The cabinet maker principle: finish what no one sees—superficiality creates nagging emptiness.
- •All work should express love and gratitude to the species.
- •Act with urgency.
- •Do what you say you will.
- •Show up on time.
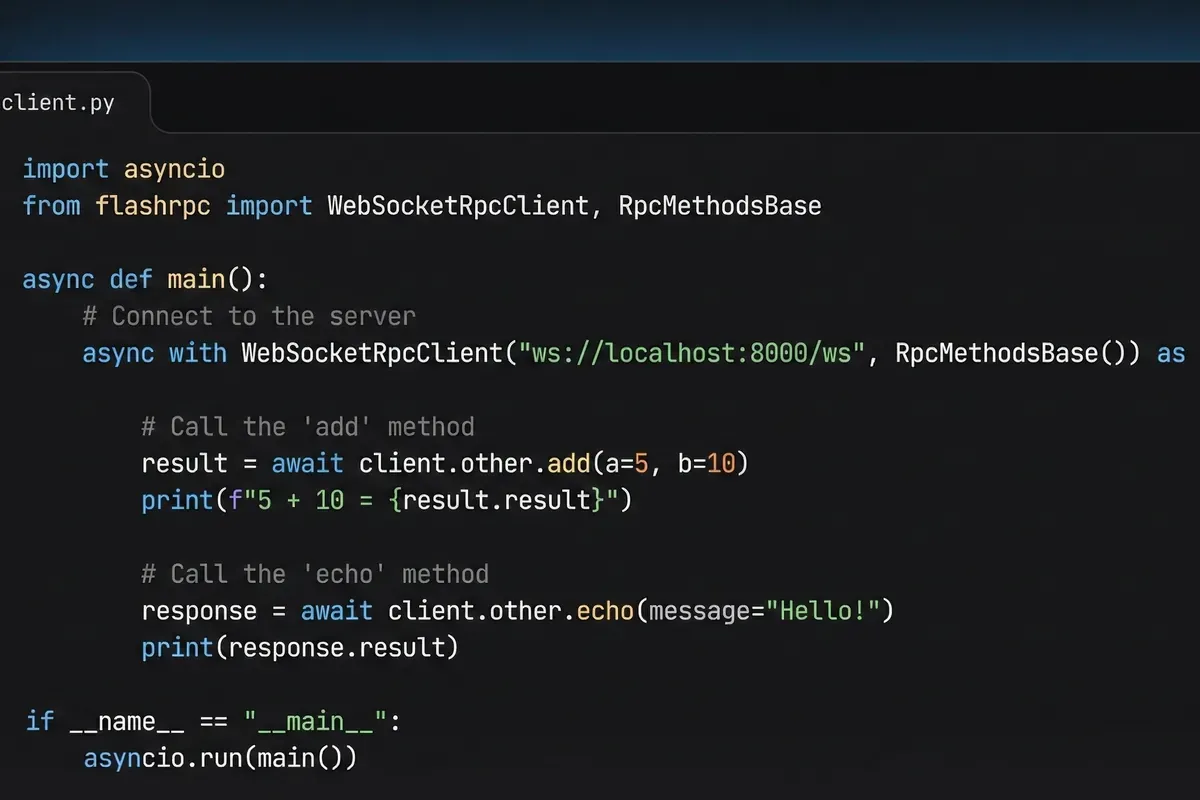
Flashrpc
rpc over websockets made easy, robust, and production ready. a fast and durable bidirectional json rpc channel over websockets.













- •Small teams who trust, love, and care about each other are fundamental.
- •Caring means actually listening, most ideas die because people just want to speak.
- •Opinions aren't ideas, greatest fear is missing amazing ideas from quiet people.
- •Make things for each other daily: creates vulnerability, gratitude, and shifts focus to others.














